Intermediate Cypher Queries
쿼리 필터링
CALL db.schema.visualization()데이터 모델 확인 명령어
CALL db.schema.nodeTypeProperties()노드의 속성 유형 확인 명령어
CALL db.schema.relTypeProperties()그래프 관계 속성 유형 확인 명령어
기본 사이퍼 쿼리-WHERE, NULL
MATCH (p:Person)-[r:DIRECTED]->(m:Movie)
WHERE r.role IS NOT NULL
AND m.year = 2015
RETURN p.name, r.role, m.title- IS NOT NULL: 관계에 대한 역할 속성이 있는지 확인하는 명령어(반대: NOT NULL)
- IN: 값이 목록 속성에 있는지 테스트 하는데 사용되는 사이퍼
평등 테스트-WHERE, =
MATCH (d:Director)-[:DIRECTED]->(m:Movie)-[:IN_GENRE]->(g:Genre)
WHERE m.year = 2000 AND g.name = "Horror"
RETURN d.name
NULL 값 쿼리-IS NULL
MATCH (m:Movie)
WHERE
m.tmdbId IS NULL
RETURN m
범위 쿼리-<,>,<=,>=
MATCH (p:Person)
WHERE p:Actor AND p:Director
AND 1950 <= p.born.year < 1960
RETURN p.name, labels(p), p.born
문자열(목록) 관련 쿼리
MATCH (p:Director)-[:DIRECTED]->(m:Movie)<-[:ACTED_IN]-(p)
WHERE "German" IN m.languages
return p.name, labels(p), m.title- IN: 문자열 목록을 포함한 값을 찾는 쿼리
MATCH (p:Person)
WHERE p.name STARTS WITH 'Robert'
RETURN p.name- START WITH: 특정 문자열로 시작하는 값을 찾는 쿼리
- EXPLAIN: 쿼리를 실행하지는 않지만 인덱스 사용 여부를 표시하는 쿼리를 반환
MATCH (m:Movie)
WHERE toUpper(m.title) STARTS WITH 'LIFE IS'
RETURN m.title- toUpper: 대문자 입력 시, 대소문자를 구분하지 않고 검색하는 쿼리
ex) LIFE IS, Life is, life is, Life Is
- toLower: 소문자 입력 시, 대소문자를 구분하지 않고 검색하는 쿼리
MATCH (p:Person)-[r]->(m:Movie)
WHERE toLower(r.role) CONTAINS "dog"
RETURN p.name, r.role, m.title- CONTAINS: 문자열이 속성 값에 있는지 검색하는 쿼리
ex) WHERE toLower(r.role) CONTAINS "dog": dog 문자열을 대소문자 구분 없이 찾는 쿼리
패턴 검색 관련 쿼리
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name = "Clint Eastwood"
AND exists { (p)-[:DIRECTED]→(m) }
RETURN m.title- exists {}: 해당 조건이 존재하는지 확인하는 쿼리(반대: NOT exists)
ex) 위 쿼리는 해당 관계가 존재하는지 확인하는 쿼리
PROFILE MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name = 'Clint Eastwood'
AND NOT exists {(p)-[:DIRECTED]->(m)}
RETURN m.title- PROFILE: 명령문을 실행하고 어떤 연산자가 대부분의 작업을 수행하는지 확인하는 쿼리 -> 성능 확인에 사용됨(데이터베이스 변경)
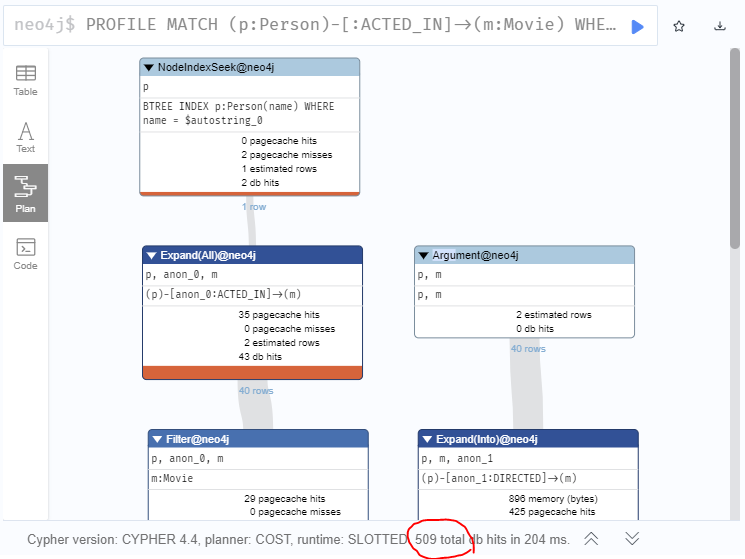
ex) 위 쿼리의 경우, 해당 쿼리가 실행될 때 총 DB 히트 수(찾는 데이터를 지나가는 수)를 확인, 결과 값은 509
- EXPLAIN: 실행 계획을 보고 싶지만, 명령문을 실행하지는 않을 때 사용하는 쿼리 -> 데이터베이스를 변경하지 않음
MATCH (p:Person)-[:DIRECTED]->(m:Movie)
WHERE p.name = 'Rob Reiner'
AND NOT exists {(p)-[:ACTED_IN]->(m)}
RETURN DISTINCT m.title- DISTINCT: 검색 결과에서 중복 제거
MATCH절 쿼리
MATCH (m:Movie) WHERE m.title = "Kiss Me Deadly"
MATCH (m)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie)
MATCH (m)<-[:ACTED_IN]-(a:Actor)-[:ACTED_IN]->(rec)
RETURN rec.title, a.name- 기본 MATCH절 예시
1. "Kiss Me Deadly"라는 이름의 Movie 노드를 검색한 뒤, m 변수에 저장한다.
2. m 변수를 모두 찾은 뒤, Kiss Me Deadly와 같은 장르로 연결된 Movice를 rec 변수에 저장한다.
3. m 변수와 rec 변수에 저장된 값 중에서, 공통되는 값, 즉 m과 rec을 같이 연기한 배우를 a 변수에 저장한다.
4. rec의 title과 a의 name을 RETURN 한다.
MATCH (m:Movie) WHERE m.title = "Kiss Me Deadly"
MATCH (m)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie)
OPTIONAL MATCH (m)<-[:ACTED_IN]-(a:Actor)-[:ACTED_IN]->(rec)
RETURN rec.title, a.name- OPTIONAL MATCH: 패턴을 검색하고, 일치하지 않는 값의 경우 NULL로 반환해줌, SQL의 외부 조인에 해당

ex) 위 쿼리의 경우
1. Kiss Me Deadly 영화를 검색한다.
2. Kiss Me Dealy와 같은 장르의 영화를 rec 변수에 저장한다.
3. Kiss Me Deadly를 연기하고, rec도 연기한 배우를 검색하는데, 이때 조건이 맞지 않는 경우(값이 없는 경우) NULL 값을 넣어준다.
4. rec의 title과 a의 name을 RETURN 한다.
즉, title 중에서 a.name이 없는 경우, 출력을 안하는게 아니라 NULL로 출력을 해준다.
정렬 및 반환 데이터 관련 쿼리-ORDER BY
MATCH (u:User)-[r:RATED]->(m:Movie)
WHERE u.name = 'Sandy Jones'
RETURN m.title AS movie, r.rating AS rating ORDER BY r.rating DESC- ORDER BY: 최저 값으로 정렬한 후 반환
- ORDER BY ~ DESC: 최고 값으로 정렬한 후 반환
- AS ~: 출력 시, ~ 값으로 테이블 컬럼 출력
* 결과에서 출력할 수 있는 최대 속성 수는 제한이 없음
MATCH (m:Movie)<-[ACTED_IN]-(p:Person)
WHERE m.imdbRating IS NOT NULL
RETURN m.title, m.imdbRating, p.name, p.born
ORDER BY m.imdbRating DESC, p.born DESCex) 위 쿼리의 경우
1. 영화에 출연한 모든 배우 중에서
2. imdbRating이 존재하는 값들을
3. title, imdbRating, name을 출력한다.
4. 단, 정렬은 imdbRating은 최고값으로, born도 최고 값(나이 어린 순)으로 정렬한다.
영화에 출연한 사람들을 연결한 뒤, born 속성으로 정렬된 사람의 이름을 반환한다. 이때 가장 높은 평가를 받은 영화에 출연한 최연소 배우를 출력하는 쿼리
데이터 개수 제한(Counting) 관련 쿼리-LIMIT, SKIP
MATCH (m:Movie) WHERE m.imdbRating is NOT NULL
RETURN m.imdbRating limit 1- DISTINCT: 중복 제거
- LIMIT: 개수 제한 출력 ex) LIMIT 100
- SKIP: 건너뛰기, 즉 데이터 시작점 ex) SKIP 40 LIMIT 100
*LIMIT을 사용하는 이유: 클라이언트에 반환되는 데이터의 양을 줄이기 위해, 쿼리에서 속성의 가장 높은 값이나 가장 낮은 값을 설정하기 위해
ex) 위 쿼리의 경우, m.imdbRating이 가장 낮은 값을 출력
조건부 관련 쿼리-CASE
MATCH (m:Movie)<-[:ACTED_IN]-(p:Person)
WHERE p.name = 'Henry Fonda'
RETURN m.title AS movie,
CASE
WHEN m.year < 1940 THEN 'oldies'
WHEN 1940 <= m.year < 1950 THEN 'forties'
WHEN 1950 <= m.year < 1960 THEN 'fifties'
WHEN 1960 <= m.year < 1970 THEN 'sixties'
WHEN 1970 <= m.year < 1980 THEN 'seventies'
WHEN 1980 <= m.year < 1990 THEN 'eighties'
WHEN 1990 <= m.year < 2000 THEN 'nineties'
ELSE 'two-thousands'
END
AS timeFrame- CASE WHEN ~ THEN ~ ELSE ~ END: WHEN절에 있는 조건에 성립할 경우 THEN을 출력, 아니면 ELSE 절에 있는 값을 출력
ex) 위 예시의 경우, WHEN 절과 ELSE 절에 맞게 조건을 판단한 후, timeFrame 컬럼으로 테이블 출력
데이터 집계(COUNTING) 쿼리-Count(), Size()
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)
WHERE a.name = 'Tom Hanks'
RETURN a.name AS actorName,
count(*) AS numMovies- count(): 데이터 집계에 사용하는 함수
ex) 위 쿼리의 경우, Tom Hanks가 출연한 영화의 수를 반환한다.
| count(n) | null 값이 아닌 n의 개수를 계산 |
| count(*) | null 값이 있는 행을 포함하여 검색된 행 수를 계산 |
count() 쿼리는 노드, 관계, 경로, 행 수를 계산하는데 사용하는 기능으로, 쿼리가 절의 모든 패턴을 처리해야 한다.
MATCH (actor:Person)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(director:Person)
RETURN actor.name, director.name,
size(collect(m)) AS collaborations,
collect(m.title) AS movies- size(): 목록의 요소 수를 반환(배열의 크기 반환)하는 함수
*count 함수는 행의 개수를 계산하거나 결과 값의 크기를 RETURN 해주지만, size 함수의 경우 list(배열)의 element(요소)의 개수를 RETURN 해준다.
| min() |
| max() |
| avg() |
| stddev() |
| sum() |
- 위 표는 size와 비슷한 함수
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)<-[r:RATED]-(:User)
WHERE p.name = 'Tom Hanks'
WITH m, avg(r.rating) AS avgRating
RETURN m.title AS Movie, avgRating AS `AverageRating`
ORDER BY avgRating DESC- avg(): 평균 값을 계산해주는 함수
위 쿼리는
1. 배우가 있고, User가 평가(RATED)한 영화를 검색한다.
2. 이때 배우는 Tom Hanks가 출연한 영화
3. m을 다시 추가해주고, 평균 평점을 avgRating으로 저장
4. 영화 이름을 출력하고, 평균 평점도 출력한다.
5. 이때 높은 평점 순으로 출력
배열(List) 관련 쿼리-Collect
MATCH (p:Person)
RETURN p.name, [p.born, p.died] AS lifeTime
LIMIT 10- [ ]: 대괄호를 사용해 List 형식으로 반환
ex) 위 쿼리의 경우, 이름과 각 사람의 출생 및 사망 값을 포함하는 lifeTime 목록을 반환
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)
RETURN a.name AS actor,
count(*) AS total,
collect(m.title) AS movies
ORDER BY total DESC LIMIT 10- collect(): 값을 목록으로 집계해주는 함수, 노드 또는 작업 결과를 모두 리스트로 만들 수 있다.ex) 위 쿼리는 각 배우와 연결된 영화 제목 목록을 반환하고, 출연한 영화 제목이 가장 많은 배우 순으로 반환
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)
WHERE m.year = 1920
RETURN collect( DISTINCT m.title) AS movies,
collect( a.name) AS actors목록에서 중복헤거를 할 때에는 위와 같이 DISTINCT를 함수 안에 넣어준다.
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)
RETURN m.title AS movie,
collect(a.name)[0] AS castMember,
size(collect(a.name)) as castSize배열이기 때문에 인덱스를 사용해서 출력할 수도 있다.
ex) 위 쿼리의 경우, 각 영화의 첫번째 출연자를 반환한다.
ex) 만약 인덱스를 [2 .. ] 으로 한다면, 인덱스 2번([2])부터 끝까지 출력한다는 의미
MATCH (m:Movie)
RETURN m.title as movie,
[x IN m.countries WHERE x = 'USA' OR x = 'Germany']
AS country LIMIT 500조건을 포함해서 배열을 만들 수도 있다.
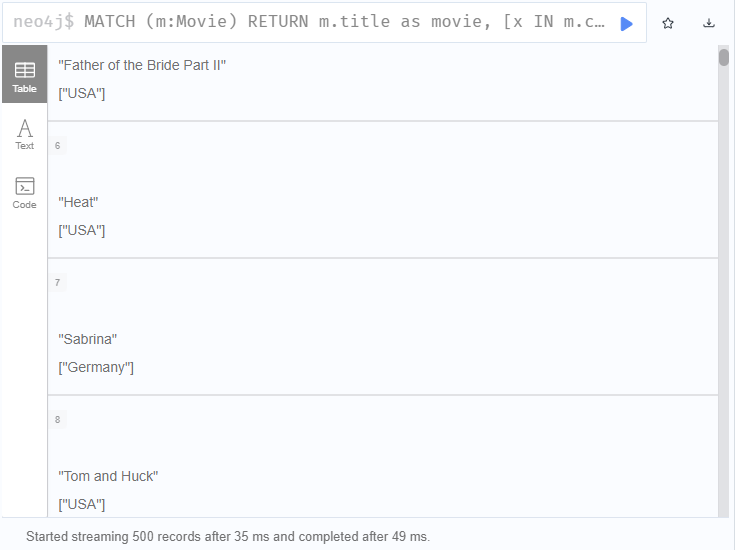
위 쿼리의 결과 값은 이와 같다.
패턴 검색(Pattern Comprehension Syntax)
MATCH (m:Movie)
RETURN m.title as movie,
[x IN m.countries WHERE x = 'USA' OR x = 'Germany']
AS country LIMIT 500양식: [<조건>|출력 값 및 형식]
조건을 포함해서 출력해주는 배열을 만들 수 있다.
패턴 이해(Pattern Comprehension)은 데이터베이스를 변경하지 않고, 리스트를 만들 수 있는 가장 좋은 방법이다.

위 예시의 결과 값은 이렇게 결과에 대한 값과 함께, 패턴 이해와 묶인 결과는 배열 형식으로 출력된다.
MATCH (a:Person {name: 'Tom Hanks'})
RETURN [(a)-->(b:Movie)
WHERE b.title CONTAINS "Toy" | b.title + ": " + b.year]
AS movies위 쿼리와 같이 결과 출력 형식을 지정해서 반환할 수도 있다.
키/값 목록(Key/Value 형식)-Map
RETURN {Jan: 31, Feb: 28, Mar: 31, Apr: 30 ,
May: 31, Jun: 30 , Jul: 31, Aug: 31, Sep: 30,
Oct: 31, Nov: 30, Dec: 31}['Feb'] AS daysInFeb형식: {key:value, key:value, ...}
사용: [key] 또는 .Key
ex) {Feb: 28, Mar: 31, Apr: 30}.Feb
RETURN keys({Jan: 31, Feb: 28, Mar: 31, Apr: 30 ,
May: 31, Jun: 30 ,Jul: 31, Aug: 31, Sep: 30,
Oct: 31, Nov: 30, Dec: 31}) AS months- keys(): 맵의 키 목록을 반환
MATCH (m:Movie)
WHERE m.title CONTAINS 'Matrix'
RETURN m { .title, .released } AS movie위와 같이 간략하게 사용해서 출력할 수도 있다. 이때 출력 값은 m에 대해 title과 released가 배열형식으로 저장되어 출력된다.
시간 작업(시간, 날짜)
MATCH (x:Test {id: 1})
RETURN duration.between(x.date1,x.date2)
//inDays의 경우
MATCH (x:Test)
RETURN duration.inDays(x.date1,x.date2).days
//.days 뿐만 아니라 hours, minutes도 가능- duration.between(): 주어진 값 2개 사이의 기간을 반환
- duration.inDays(x.datetime1,x.datetime2).days: 주어진 값 2개 사이의 기간을 일 단위로 반환
MATCH (x:Test {id: 1})
RETURN x.date1 + duration({months: 6})- duration({months: 6}): 6개월의 기간을 더해줌
ATCH (x:Test {id: 1})
RETURN x.datetime as Datetime,
apoc.temporal.format( x.datetime, 'HH:mm:ss.SSSS')
AS formattedDateTime
//또는
MATCH (x:Test {id: 1})
RETURN apoc.date.toISO8601(x.datetime.epochMillis, "ms")
AS iso8601- apoc.temporal.format(): APOC 형식으로 시간을 출력하는 함수
- apoc.date.toISO8601(): APOC 형식으로 시간을 출력하는 함수
가변 길이 순회
MATCH (a:Person{name:'Robert Blake'})-[:ACTED_IN*1..4]-(b:Person)
RETURN DISTINCT b.name- (x)-[:relation*1..6]-(y): x에서 y까지 1에서 6만큼 떨어진 목록을 반환하는 명령, 즉 최대 6홉 떨어진 목록을 반환한다.
- (x)-[:relation*6]-(y): x에서 y까지 6만큼 떨어진 목록을 반환하는 명령
- shortestPath(): 두 노드 사이의 최단 경로를 반환하는 함수
범위 지정 변수-WITH
WITH 'Clint Eastwood' AS a, 'high' AS t
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WITH p, m, toLower(m.title) AS movieTitle
WHERE p.name = a
AND movieTitle CONTAINS t
RETURN p.name AS actor, m.title AS movie- WITH: 쿼리에서 변수의 범위를 재정의하는데 사용되는 명령으로, WITH 절을 지나면 변수가 초기화 됨으로 다시 추가해주는 작업을 수행해줘야 한다.
WITH 'Tom Hanks' AS theActor
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name = theActor
AND m.revenue IS NOT NULL
WITH m ORDER BY m.revenue DESC LIMIT 1
RETURN m.revenue AS revenue, m.title AS title위 쿼리의 경우
1. Tom Banks라는 문자열을 theActor라는 변수로 저장한다.
2. m을 연기한 p를 저장한다.
3. 이때 조건은 p.name이 theActor('Tom Hanks')여야 한다.
4. 그리고 m.revenue는 NULL이면 안된다.
5. m을 다시 추가해 주는데, revenue가 가장 높은 것 1개를 추가한다.
6. 추가된 m을 출력한다.
즉, 위 쿼리는 수익(revenue)가 가장 높은 영화가 반환되도록 하는 쿼리이다.
MATCH (n:Movie)
WHERE n.imdbRating IS NOT NULL AND n.poster IS NOT NULL
WITH n {
.title,
.imdbRating,
actors: [ (n)<-[:ACTED_IN]-(p) | p { tmdbId:p.imdbId, .name } ],
genres: [ (n)-[:IN_GENRE]->(g) | g {.name}]
}
ORDER BY n.imdbRating DESC
LIMIT 4
RETURN collect(n)위 쿼리는
1. Movie n을 검색하는데
2. imdbRating 과 post 가 NULL이 아닌 것을 검색한다.
3. 제목, imdbRating, 배우 이름 목록, 장르 이름목록을 포함하도록 지정한다.
4. imdbRating이 높은 순으로
5. 상위 4개를 출력한다.
6. 결과를 1개의 리스트로 출력한다.
배열 풀기(Unwinding Lists)-UNWIND
- UNWIND: collect()를 사용해 만든 리스트를 풀고, 각 요소에 액세스 할 수 있도록 하는 명령어
MATCH (m:Movie)-[:ACTED_IN]-(a:Actor)
WHERE a.name = 'Tom Hanks'
UNWIND m.languages AS lang
RETURN m.title AS movie,
m.languages AS languages,
lang AS language위 쿼리의 경우
1. Tom Hanks가 출연한 영화를 검색한다.
2. 이때 언어 속성이 해제되고, 각 값이 lang으로 참조된다.
3. 반환되는 행은 여러 행과 lang 값에 대해 반복되는 영화 제목과 언어 속성이다.

위 쿼리를 실행하면 위와 같은 결과가 나온다. 그냥 출력했을 때(UNWIND 없이)는 대괄호에 묶여 리스트 형태로 출력되지만, UNWIND를 실행한 값의 경우 그냥 문자열로 요소로 출력된다.
MATCH (m:Movie)
UNWIND m.languages AS lang
WITH m, trim(lang) AS language
// this automatically, makes the language distinct because it's a grouping key
WITH language, collect(m.title) AS movies
RETURN language, movies[0..10]- trim(): 불필요한 공백을 제거해주는 명령어
하위 쿼리-CALL, UNION
MATCH (m:Movie)
CALL {
WITH m
MATCH (m)<-[r:RATED]-(u:User)
WHERE r.rating = 5
RETURN count(u) AS numReviews
}
RETURN m.title, numReviews
ORDER BY numReviews DESC- CALL: 절에서 반환된 노드들을 다음 하위 쿼리에서 사용할 수 있도록 만들어주는 명령어
위 쿼리에서
1. 모든 영화에 대한 m을 반환한다.
2. Movie 노드 m을 CALL을 사용해 하위 쿼리에 전달한다.
3. 하위 쿼리 내에서 쿼리가 실행되어 해당 영화에 5점을 부여한 모든 사용자를 찾아 계산한다.
4. 하위 쿼리 CALL은 개수를 반환단다.
5. 하위 쿼리 CALL을 벗어나 제목이 반환디고, CALL 내에서 반환된 numReviews도 반환된다.
MATCH (g:Genre)
CALL {
WITH g
MATCH (g)<-[:IN_GENRE]-(m) WHERE 'France' IN m.countries
RETURN count(m) AS numMovies
}
RETURN g.name AS Genre, numMovies ORDER BY numMovies DESC위 쿼리는 국가 목록 요소가 'France'인 영화 노드를 반환하는 쿼리이다.
1. 하위 쿼리에 WITH로 g변수를 전달한다.
2. 해당 장르의 영화의 countries가 France인 것을 검색한다.
3. 각 장르에 대해 영화 노드 수인 numMovies를 반환한다.
MATCH (m:Movie) WHERE m.year = 2000
RETURN {type:"movies", theMovies: collect(m.title)} AS data
UNION ALL
MATCH (a:Actor) WHERE a.born.year > 2000
RETURN { type:"actors", theActors: collect(DISTINCT a.name)} AS data- UNION: 쿼리가 복잡해짐에 따라 여러 쿼리의 결과를 결합할 때 사용한다. 이때, 결합하는 쿼리는 동일한 수의 속성 또는 데이터를 반환해야 한다.
- UNION ALL: 같은 데이터 형식을 반환할 때 결과를 결합할 수 있다.
MATCH (p:Person)
WITH p LIMIT 100
CALL {
WITH p
OPTIONAL MATCH (p)-[:ACTED_IN]->(m:Movie)
RETURN m.title + ": " + "Actor" AS work
UNION
WITH p
OPTIONAL MATCH (p)-[:DIRECTED]->(m:Movie)
RETURN m.title+ ": " + "Director" AS work
}
RETURN p.name, collect(work)위 쿼리와 같이 하위 쿼리 CALL과 UNION을 함께 사용할 수 있다.
1. Person p에 대해 검색하는데
2. 상위 100개까지만 검색한다
3. 해당 인물(p)이 영화에서 연기한 경우 "Actor"이라는 접미사와 제목을 work라는 이름으로 반환한다.
4. 해당 인물(p)이 영화를 감독한 경우 "Director"이라는 접미사와 제목을 work라는 이름으로 반환한다.
5. 3,4번의 두 결과가 모두 work 이기 때문에 UNION으로 병합시켜준다.
5. 이름과 work 목록을 반환한다.
매개변수-$
Cypher문을 테스트할 때 다양한 리터럴 값을 사용하여 Cypher 쿼리가 올바른지 확인해야 한다. 하지만 테스트 할 때마다 Cypher 문을 변경하고 싶지는 않을 때, 쿼리에서 매개변수를 사용해 대체하여 Cypher 문을 만든다. 실제로 Cypher 문을 변경하려면 많은 비용이 들기 때문에, 가장 좋은 방법은 Cypher 문에서 값을 매개변수화 하는 것이다.
:param actorName: 'Tom Hanks':param ~: :매개변수를 설정하는 명령
ex) 위 쿼리는 actorName이라는 매개변수를 설정하는 명령이다.
※이때 띄어쓰기 유의할 것! :param 매개변수명:(space)값
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name = $actorName
RETURN m.released AS releaseDate,
m.title AS title
ORDER BY m.released DESC- $: Cypher 문에서 매개변수 이름은 $ 기호로 시작한다.
ex) 위 쿼리는 $actorName이라는 매개변수를 사용한 예시이다.
:param number: 10 //일반 사용
:param number=> 10 //숫자를 정수로 강제로 변경할 때- 정수 값 매개변수 설정
- => 10: 숫자를 정수로 강제 형변환을 할 때에는 => 연산자를 사용한다.
:params {actorName: 'Tom Cruise', movieName: 'Top Gun'}- 여러 매개 변수 설정
:params- :params: 매개변수 보기(출력), 현재 매개변수와 해당 값을 확인할 수 있다.
:params {}- :params {}: 매개변수 제거(삭제)
세션에서 기존 매개변수를 제거하려면 JSON 형식 구문을 사용해 제거한다.
전제 매개변수 삭제는 {}를 사용한다.

와~~! 인증서 받기 앙 성공띠리링~
'Cloud SIEM 제작 > Graph DB(Neo4j)' 카테고리의 다른 글
| [Neo4j] Graph Data Science-그래프 카탈로그(Graph Catalog) (0) | 2023.01.04 |
|---|---|
| Neo4j Graph Data Science(GDS) 개요 (0) | 2023.01.04 |
| Neo4j 기본 명령어 모음 (2) | 2022.10.25 |
| Neo4j 기본 사용법 (0) | 2022.09.16 |
| Neo4j에 대해서 (개념/순위/특징/기능) (1) | 2022.09.16 |




댓글